Stacks are a computer science data structure useful for special types of computation where you essentially add information to the top of the ‘stack’ and also remove information only from the top of the stack. LIFO stands for Last-In-First-Out, which is an acronym that aids in remembering what is going on in a stack, i.e. the last item added to the to the stack is the first item that will be removed from the stack.
In Python, a stack can be implemented as an array where we use built-in Python methods such as list.append() which can ‘push’ information onto the stack and list.pop() which can ‘pop’ information off of the stack.
Both of these methods act on the end of an array, so all we have to do to visualize a Python list as a stack is turn the array 90 degrees counter clockwise so that the front of the array is at the bottom and the end of the array is considered the ‘top’ of the stack. Or, you can just imagine the horizontal end of a Python list as the top of the stack.
Here is what Wikipedia says about stacks:
In computer science, a stack is an abstract data type that serves as a collection of elements, with two principal operations:
push, which adds an element to the collection, and
pop, which removes the most recently added element that was not yet removed.
Here is one way to visualize what is going on in a stack:
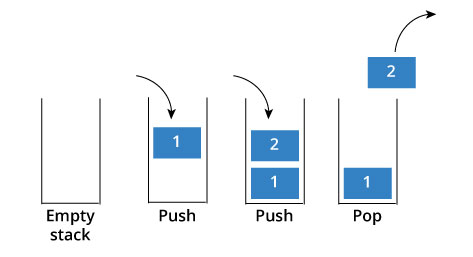
Next I will illustrate how a stack can be useful in solving real problems. Let’s say I am creating a parser that reads every line of a source code file looking for opening and closing parenthesis in order to capture all function calls. The parser is working except it is finding function calls that should not be included because they are inside of larger strings such as HTML constructions or SQL queries. For example, here is an HTML construction that contains function calls that should be ignored due to the fact that the calls are inside of a string.
html += '<p><a href="#" onclick="javascript:$(\'#help_note\').hide();">Close</a></p>';
Technically there are function calls inside this string, but I don’t want to capture them because I am trying to gather only function calls that are actually being used in the surrounding code. Notice this string is surrounded by single quotes, then it has some double quotes inside, followed by more double quotes with single quotes inside them.
![]()
The problem is, how do you parse this line so that you can tell where the string begins and ends? You can’t just go to the next occurrence of single quote that you find, because it is inside of another double quote inside the string. Counting single and double quotes like you would count opening and closing brackets won’t work either, because you don’t know ahead of time how long the string is so you don’t know if any given quotes you find are the last.
This is where the concept of a stack becomes really useful. When reading a line of text like the above example, character by character from left to right, whenever we encounter a single or double quote, we can add it to the stack. Because we have both single and double quotes, we need to represent them differently in the stack. For example, we could call the single quotes ‘s’ and the double quotes ‘d’.
The algorithm works like this:
If we see a single quote, push an ‘s’ onto the stack. If we see a double quote, push a ‘d’ onto the stack. However, before adding an ‘s’ or ‘d’ to the stack, check the top of the stack to see if it matches what we just found. For example, if I just found double quotes, check the top of the stack. If the top of the stack already contains a ‘d’, then pop the ‘d’ off of the stack. Otherwise, push a ‘d’ onto the stack.
This works the same way for ‘s’. When encountering a new single quote in the string, if the top of the stack already contains an ‘s’, then pop it off of the stack. Otherwise, push an ‘s’ onto the stack.
Now all we have to do to find the end of the string is to check the stack to see if it is empty. If the stack is empty, we have found the end of the string and we are done.
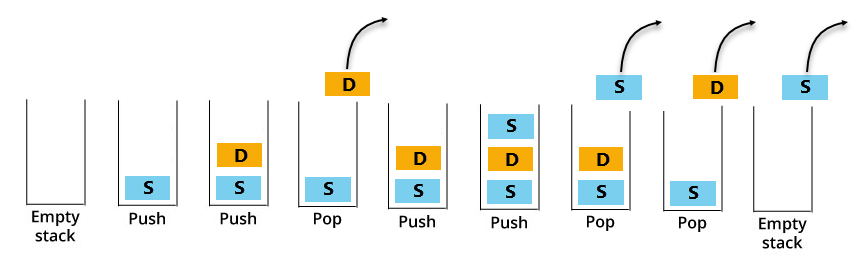
Here is how this plays out with the example string above:
- Encountered a single quote. The top of the stack doesn’t contain an ‘s’ already, so push an ‘s’ onto the stack.
- Next we encounter a double quote. The top of the stack doesn’t contain a ‘d’, so push a ‘d’ onto the stack.
- Next we encounter a double quote again. The top of the stack does contain a ‘d’ already, so pop the ‘d’ off of the top of the stack.
- Next we encounter a double quote. The top of the stack doesn’t contain a ‘d’, so push a ‘d’ onto the stack.
- Next we encounter a single quote. The top of the stack doesn’t contain an ‘s’, so push an ‘s’ onto the stack.
- Next we encounter a single quote again. The top of the stack does contain an ‘s’, so pop the ‘s’ off of the top of the stack.
- Next we encounter a double quote again. The top of the stack does contain a ‘d’, so pop the ‘d’ off of the top of the stack.
- Next we encounter a single quote again. The top of the stack does contain an ‘s’, so pop the ‘s’ off of the top of the stack.
- Now the stack is empty, so we are done. We have found the end of the string.
Here is what the Python algorithm looks like:
sq = "'"
dq = '"'
nonQuoteLine = ""
quoteStack = []
if sq in line or dq in line:
for char in line:
if char == sq:
if len(quoteStack) == 0:
quoteStack.append('s')
else:
if quoteStack[-1] == 's':
quoteStack.pop()
else:
quoteStack.append('s')
elif char == dq:
if len(quoteStack) == 0:
quoteStack.append('d')
else:
if quoteStack[-1] == 'd':
quoteStack.pop()
else:
quoteStack.append('d')
if len(quoteStack) == 0:
nonQuoteLine += char
For more good information about LIFO stacks, see:
https://www.i-programmer.info/babbages-bag/263-stacks.html
For more information about Python methods append() and pop(), see:
https://www.tutorialspoint.com/python/list_append.htm
https://docs.python.org/3.1/tutorial/datastructures.html